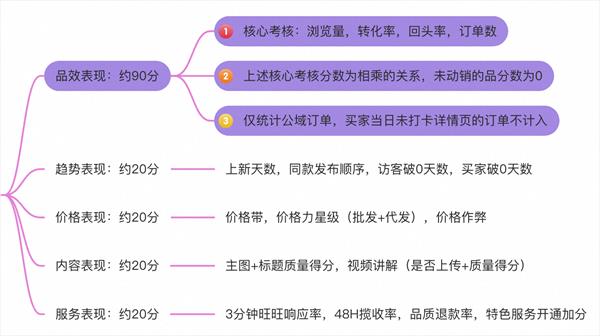
用户偏好分析是一个比较大的题目,哪怕只是将它局限在网站分析领域中,也可以从各种角度入手来了解你的网站用户。限于篇幅和笔者本身的能力,这里将介绍的是笔者认为比较实用的,也认为是容易上手和扩展的方法,也同时希望能够起到抛砖引玉的效果。
熟悉网站分析的朋友们都知道,GA(GoogleAnalytics)中可以关联不同的维度(Dimension),比如“城市”和“产品”,通过关联(Sub-relation),我们可以得到不同城市下,各产品的相关数据。在Omniture的几个网站分析工具中,也同样能够对某个eVar根据按另一个eVar来breakdown。
Step1.获取数据
1.a请生成一张报表,
维度(Dimension):城市(Cities)
指标(Metric):购买数量/销量(Units)
时间段可根据需要设定,时间粒度(Granularity)在Omniture中选None/aggregate,表示把时间以聚合的方式展现,而不是按daily、monthly等方式来划分,GA中同理。
好了,我们得到了一张关于各个城市的访客所产生的订单数的报告,第三列Ratio是经过计算得到的各城市订单数占总体的比例。这里假定了只有图表中所列出的10个城市,所有数据均为模拟数据。
1.b类似上一张城市报告,我们再获得一份产品类(ProductCategory)的报告,维度:Category,指标:Units,获得的报告如下
*这里需要注意,你所看到的两张表中的Units总量是一样的,但如果你选择了Orders作为Metric的话,那么品类报告中的Orders应该会大一些,因为有些用户的单个订单横跨了不同的产品类。比如实际情况是你下了一个订单,包含了一台VAIO和一台DSC,那么在产品类报告中这1个订单会被分拆为2个,各自归属到2个品类中。如果Orders总量相差不大,那不用太在意这个差异,如果你觉得差异让你无法接受的话,那也不难,对城市报告中的数据做个简单处理:处理后各城市订单数=处理前各城市订单数*(产品类报告订单总数/处理前城市订单总数)。但是这样的处理会稍许影响到后续介绍的计算过程,当然,只要你保持头脑清醒,相信在理解了算法后根据需要来修改也不是难事。
1.c获得一份Sub-relation的报告,第一个维度选择城市,第二个维度选产品类,指标仍然是Units,报表如下:
限于篇幅,图中只显示了Shanghai的数据,实际应该是所有其它城市都会得到跟Shanghai类似结构的数据。由于本例中共有10个城市和10个产品类,因此得到的数据应该是10*10=100行。同样,这里的Units总量应该与之前的相同。
从表中我们可以知道,在Shanghai所产生的962个Units中,VAIO占了378个,DSC占了112个,这个很容易理解。
Step2.数据处理
如上图所示,我们在1.c报表的基础上,新增一列PredictedUnits,作为我们预测的商品销量,怎么计算呢?PredictedUnits=1.a中Shanghai的Units*1.b中VAIO的Ratio(或者1.a中Shanghai的Ratio*1.b中VAIO的Units也是一样的)
然后我们再新增一列Difference,表示实际值与预测值的差异程度,计算方式为:
Difference=(Units–PredictedUnits)/PredictedUnits
Step3.数据解读
不难理解,如果实际值大于预测值,Difference为正,反之为负,实际值与预测值差异越大,Difference的绝对值越大。
既然需要的数据都有了,该怎么看我们用户的偏好呢?如何去发现那些有价值的信息呢?
Difference一列中,最抓人眼球(eye-catching)的显然是Shanghai-DSC那行了,372%。这表示,Shanghai的用户比我们想象中的更热衷于DSC产品,而且是远远大于预期。同样,VAIO、Tablet等产品在Shanghai用户中的销售情况也比我们的预期要好。而HIFI的-80%,MDR的-59%,说明了Shanghai的用户对这些产品并不是非常感兴趣。当然,如果在做这个分析前,你已经对你的某些产品做了定向投放,那么会一定程度上影响该报告的解读,这时候,我的建议是:
1.casebycase的来分析那些定向投放了的产品,需要综合考虑你的投放情况及业务情况
2.剔除那部分定向投放了的产品及密切相关的产品,从而解读那些未受太大影响的产品数据。
到这里,如果在读这篇文章的你正从事OnlineMarketing等相关的工作,不知道有没有能够触动到你的神经呢?SEM、adwords等广告投放平台中的地理位置定位,能通过这个分析得到改进吗?花钱买的广告,真的投放给那些感兴趣的用户了吗?……
本文所谓的预测,并没有基于什么很高级的算法,只是先假定了我们的所有用户的偏好是一致的,基于这个假设,两个维度关联后的情况应当与两个维度独立时所推断的情况一致。还是举个简单的例子来说明吧。假定双胞胎姐妹总共吃了4个水果,又知道水果中香蕉被吃了2个,苹果也被吃了2个。如果姐妹俩的偏好一致,我们可以认为姐妹应该各自吃了1个香蕉1个苹果。然而真实的情况是姐姐吃了2两个香蕉,妹妹吃了2两个苹果,也就是说,姐姐比我们所认为的多吃了1个香蕉而少吃了1个苹果,那么她的偏好应该是爱吃香蕉而不爱吃苹果。
当然,这样的预测方法由于少考虑了很多因素而并变得不是很精准,但笔者认为,这不会是什么很大的问题。虽然我们的计算过程是定量的,但我们的目的只是定性而已,380%的Difference在这个方法中跟370%没有什么太大的区别。而且,以损失一些精度为代价,获得更高的效率并非什么不可原谅的事,毕竟我们是在商场里作战,而不是在学校码论文。
最后想说的是,本文所举例子是不同城市用户关于不同产品类的购买偏好分析,实际上,朋友们完全可以根据自己的业务需求来驱动类似的分析,比如关联用户的操作系统(OperatingSystem)和浏览器(Browser),指标选择访问数(Visits),便能了解到你网站的用户在不同操作平台上更喜欢用哪种浏览器。
理论上来说,任意两个维度都可以关联起来,且能说明些问题,但不建议强行地去关联两个维度,然后绞尽脑汁地去赋予它某种意义,不要为了分析而分析。还是那句话,以业务需求来确定分析目标,再以分析结果来驱动业务发展。
【版权声明】行行出状元平台欢迎各方(自)媒体、机构转载、引用我们原创内容,但要严格注明来源:;同时,我们倡导尊重与保护知识产权,如发现本站内容存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至service@hhczy.com,我们将及时沟通与处理。